上一篇文章分析了FlinkX自定义的BaseRichInputFormat类,子类只需要实现openInternal和nextRecordInternal等xxxInternal方法。本篇文章继续分析BaseRichInputFormat是如何实现统一的指标收集、发布功能。
FlinkX源码剖析(5)
· 13 min read

Never settle down
上一篇文章分析了FlinkX自定义的BaseRichInputFormat类,子类只需要实现openInternal和nextRecordInternal等xxxInternal方法。本篇文章继续分析BaseRichInputFormat是如何实现统一的指标收集、发布功能。
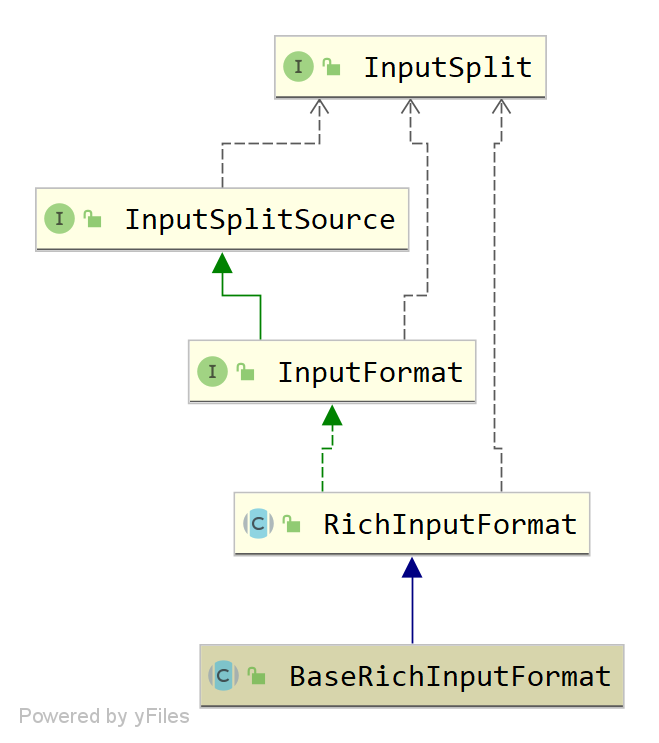
上一篇文章分析了DtOutputFormatSinkFunction,其run方法本质还是调用InputFormat.nextRecord生成输出记录。由于FlinkX连接器插件的xxxInputFormat都继承自定义的BaseRichInputFormat类(继承关系如下图所示),这篇文章继续按照该图从上到下地解析源码。
对于JDBC读插件工厂类JdbcSourceFactory,其createSource方法调用createInput方法,返回DataStream完成输入流接入,代码如下:
protected DataStream<RowData> createInput(
InputFormat<RowData, InputSplit> inputFormat, String sourceName) {
Preconditions.checkNotNull(sourceName);
Preconditions.checkNotNull(inputFormat);
/**
* 构造source算子提供一个InputFormat和一个TypeInformation
* DtInputFormatSourceFunction类没有被继承,
* 因此是所有数据源SourceFunction的包装类
* 它封装了inputFormat和TypeInformation,产生数据流由inputFormat提供
* 所以inputFormat才是sourceconnector异化的本质
*/
DtInputFormatSourceFunction<RowData> function =
new DtInputFormatSourceFunction<>(inputFormat, getTypeInformation());
// 添加source算子,算子名称是工厂类名的全小写模式,如mysqlsourcefactory
return env.addSource(function, sourceName, getTypeInformation());
}
由于JdbcSourceFactory的子类如MysqlSourceFactory等都没有重写createSource方法,因此env.addSource添加的SourceFunction都是DtInputFormatSourceFunction,只不过各子类InputFormat不同而表现差异化。DtInputFormatSourceFunction类继承关系如下图所示,本篇文章就其涉及的Flink核心类按从上到下的顺序进行源码解析,进一步熟悉Flink API。
开发Flinky时发现,FlinkX的BashRichInputFormat类使用RowData作输出类型,而Flink JDBC connector模块的JdbcInputFormat类使用Row作为输出类型。今天就写篇文章研究下它们的区别,最后给出Flinky到底该使用Row还是RowData。
📝如何用Java来实现LRU和LFU两种算法
📝HashMap知识点总结:包含HashTable、HashMap、ConcurrentHashMap
📝MySQL知识点总结。
📝Redis知识点总结。
📝Hive 3.1.2学习笔记第6篇:Hive调优。
📝Hive 3.1.2学习笔记第5篇:文件压缩和存储。