
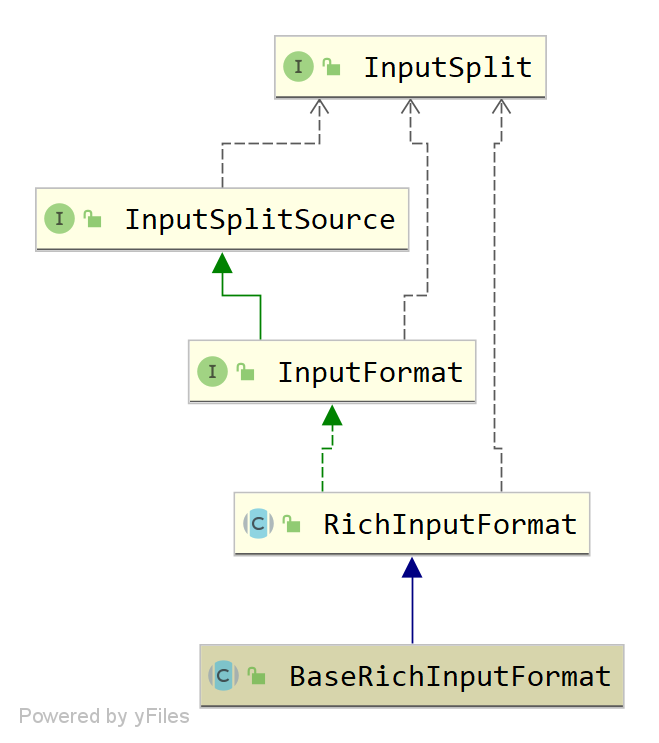
上一篇文章分析了DtOutputFormatSinkFunction,其run方法本质还是调用InputFormat.nextRecord生成输出记录。由于FlinkX连接器插件的xxxInputFormat都继承自定义的BaseRichInputFormat类(继承关系如下图所示),这篇文章继续按照该图从上到下地解析源码。
InputSplit
InputFormat并不是一股脑地输出所有记录,而是按照某种逻辑划分为split(分片),只负责分配到自己的split。顾名思义,InputSplit是划分给InputFormat的split的基本抽象,该接口只定义了一个方法getSplitNumber,用于返回split的序号:
public interface InputSplit extends Serializable {
int getSplitNumber();
}
InputSplitSource
InputSplitSource泛型接口是创建InputSplit的抽象表达,源码如下:
public interface InputSplitSource<T extends InputSplit> extends Serializable {
T[] createInputSplits(int minNumSplits) throws Exception;
InputSplitAssigner getInputSplitAssigner(T[] inputSplits);
}
T[] createInputSplits(int minNumSplits) throws Exception
创建不少于minNumSplits个的InputSplit,返回数组。
InputSplitAssigner getInputSplitAssigner(T[] inputSplits)
传入InputSplit数组,返回安排哪些InputSplit到哪些InputFormat的分配器InputSplitAssigner,这里又引出了一个新接口。
InputSplitAssigner
InputSplitAssigner负责将InputSplit分配到数据源的不同实例,定义了如下2个方法:
InputSplit getNextInputSplit(String host, int taskId)
返回指定id任务的下一个InputSplit,如果没有则返回null。注意这里也将任务示例所处ip也作为参数传入,从而实现本地分配。
void returnInputSplit(List<InputSplit> splits, int taskId)
失败回调方法,由指定id的任务通知InputSplitAssigner哪些InputSplits它处理失败了。
InputFormat
SourceFunction是Flink流数据源的基本接口,而InputFormat接口是生成记录的数据源的基本接口(来自源码注释,有点咬文嚼字了),后者负责如下功能:
- 描述如何将input分成split;
- 描述如何从split中读取记录;
- 描述如何从input中收集统计指标。
具体地,InputFormat生命周期如下:
- 通过无参构造器实例化,由configure方法进行配置;
- [可选]生成基本统计指标;
- 生成InputSplit;
- 每个并行任务创建一个InputFormat实例,根据指定split配置、打开实例;
- 从InputFormat中读取记录;
- 关闭InputFormat。
注意
InputFormat示例关闭后必须能够重新打开,因为该示例负责处理多个split。当处理完一个split后,InputFormat的close方法被调用,如果有下一个split待处理,重新调用open方法打开。
InputFormat泛型接口签名如下,泛型参数OT表示输出类型,T表示InputSplit类型。
public interface InputFormat<OT, T extends InputSplit>
extends InputSplitSource<T>, Serializable {
...
}
InputFormat接口声明如下方法:
void configure(Configuration parameters)
由于InputFormat通过无参构造器实例化,需要通过Configuration提供基本的配置,该方法在InputFormat实例化后立即调用。
BaseStatistics getStatistics(BaseStatistics cachedStatistics) throws IOException
传入缓存统计值,返回最新统计值。可以直接返回null或者cachedStatistics,保证在configure方法之后调用。
T[] createInputSplits(int minNumSplits) throws IOExceptionInputSplitAssigner getInputSplitAssigner(T[] inputSplits)
继承自InputSplitSource接口的方法,见InputSplitSource。
void open(T split) throws IOException
根据指定split分片打开一个并行InputFormat示例,保证在configure方法之后调用。
boolean reachedEnd() throws IOException
检查当前split处理是否已经完毕,保证在configure方法之后调用。
OT nextRecord(OT reuse) throws IOException
输出下一条记录,保证在configure方法之后调用。
void close() throws IOException
当前split处理完毕后调用,用于关闭通道、释放资源。只有当该方法成功返回后,InputFormat才算正确读取记录。
BaseStatistics
BaseStatistics是InputFormat基本统计指标的抽象接口,声明如下方法:
public long getTotalInputSize()
获取InputFormat总共输出的数据大小(单位:字节)。
public long getNumberOfRecords()
获取InputFormat总共输出的记录条数。
public float getAverageRecordWidth()
获取InputFormat平均输出的记录大小(单位:字节)。
可以发现,统计指标方法返回基本类型而不是包装类,因此不能返回null表示该指标无法统计,BaseStatistics内定义了如下常量来表示这种情况:
/** Constant indicating that the input size is unknown. */
@PublicEvolving public static final long SIZE_UNKNOWN = -1;
/** Constant indicating that the number of records is unknown; */
@PublicEvolving public static final long NUM_RECORDS_UNKNOWN = -1;
/** Constant indicating that average record width is unknown. */
@PublicEvolving public static final float AVG_RECORD_BYTES_UNKNOWN = -1.0f;
tip
BaseStatistics的源码注释为Interface describing the basic statistics that can be obtained from the input,查看OutputFormat源码发现它没有声明getStatistics方法,哪为什么OutputFormat没有指标统计方法?
RichInputFormat
RichInputFormat抽象类实现InputFormat接口(但没有实现其任何方法),通过添加runtimeContext字段实现对运行上下文环境的访问(即Rich的含义),并额外添加如下方法:
public void setRuntimeContext(RuntimeContext t)public RuntimeContext getRuntimeContext()
运行时上下文的setter和getter方法
public void openInputFormat() throws IOException
打开InputFormat实例,仅在每个并行format实例上调用一次,用于分配资源,比如数据库连接等。方法体为空,由子类实现。
public void closeInputFormat() throws IOException
关闭InputFormat实例,仅在每个并行format实例上调用一次,用于关闭openInputFormat中的资源。方法体为空,由子类实现。
InputFormat对比RichInputFormat
- 从继承关系上看,RichInputFormat抽象类实现了InputFormat接口;
- 从功能特性上看,RichInputFormat引入runtimeContext字段,并通过setter/getter方法实现运行环境的访问;而InputFormat接口不具备这种Rich特性;
- 从声明方法上看,RichInputFormat继承了InputFormat所有方法,但都没有实现;相反,还自行引入了openInputFormat和closeInputFormat方法。
tip
InputFormat的open/close方法处理对象是InputSplit(范围的抽象),所以open方法需要传入参数,而RichInputFormat的openInputFormat/closeInputFormat方法处理对象是数据资源(数据库连接等),且两个方法都是无参。
BaseRichInputFormat
BaseRichInputFormat是FlinkX中所有自定义InputFormat的抽象基类,继承自RichInputFormat<RowData, InputSplit>,因此所有输出记录类型为RowData。定义如下字段和方法:
成员变量
| 修饰符 | 类型 | 名称 | 说明 |
|---|---|---|---|
| private final | AtomicBoolean | isClosed | 标志InputFormat是否输出所有记录 |
| protected | StreamingRuntimeContext | context | 运行环境,本质是父类RichInputFormat的RuntimeContext转换而来 |
| protected | String | jobName | 任务名称,默认defaultJobName |
| protected | String | jobId | 任务id |
| protected | int | indexOfSubTask | 当前任务索引 |
| protected | long | startTime | 任务开始时间 |
| protected | FlinkxCommonConf | config | 任务配置 |
| protected | AbstractRowConverter | rowConverter | 数据类型转换器 |
| protected transient | BaseMetric | inputMetric | 统计指标对象 |
| protected transient | CustomReporter | customReporter | 指标发布器 |
| protected | AccumulatorCollector | accumulatorCollector | 累加器 |
| protected | FormatState | formatState | 检查点状态缓存 |
| protected | LongCounter | numReadCounter | 读取记录条数 |
| protected | LongCounter | bytesReadCounter | 读取记录字节数 |
| protected | LongCounter | durationCounter | 读取记录时长 |
| protected | ByteRateLimiter | byteRateLimiter | 限流器 |
| private | boolean | initialized | BaseRichInputFormat是否初始化,默认false |
| protected | List<String> | columnNameList | 任务配置非常量字段的名称列表 |
| protected | List<String> | columnTypeList | 任务配置非常量字段的类型列表 |
成员方法
- configure:方法体还是为空,有点鸡肋🐤;
- getStatistics:返回null,统计指标已经在上面的定义字段中有了,这里不用Flink提供的BaseStatistics接口;
- createInputSplits:调用自定义方法createInputSplitsInternal实现;
揣测
为什么BaseRichInputFormat要自己定义createInputSplitsInternal然后createInputSplits调用该方法,这样包一层的意义是什么?原因是FlinkX的JDBC读插件需要连接数据库查询,对于可能抛出的SQLException,createInputSplits签名中的throw IOException无法让上层代码感知,所以新增createInputSplitsInternal方法,签名使用throw Exception。
- getInputSplitAssigner:使用Flink提供的DefaultInputSplitAssigner,按照顺序依次分组;
- open:继承自InputFormat的方法;
public void open(InputSplit inputSplit) throws IOException {
this.context = (StreamingRuntimeContext) getRuntimeContext();
if (inputSplit instanceof ErrorInputSplit) {
throw new RuntimeException(((ErrorInputSplit) inputSplit).getErrorMessage());
}
// 一些辅助工具的初始化工作,先跳过
if (!initialized) {
initAccumulatorCollector();
initStatisticsAccumulator();
initByteRateLimiter();
initRestoreInfo();
initialized = true;
}
openInternal(inputSplit);
LOG.info(
"[{}] open successfully, \ninputSplit = {}, \n[{}]: \n{} ",
this.getClass().getSimpleName(),
inputSplit,
config.getClass().getSimpleName(),
JsonUtil.toPrintJson(config));
}
open方法完成公共操作,比如给自己的context字段赋值,检查InputSplit是否为ErrorInputSplit,进行初始化工作并设置initialized为true,最后调用自定义方法openInternal开始读取记录,而openInternal抽象方法又由子类实现。
- openInputFormat:继承自RichInputFormat,完成部分字段的初始化工作;
public void openInputFormat() throws IOException {
Map<String, String> vars = getRuntimeContext().getMetricGroup().getAllVariables();
if (vars != null) {
jobName = vars.getOrDefault(Metrics.JOB_NAME, "defaultJobName");
jobId = vars.get(Metrics.JOB_NAME);
indexOfSubTask = Integer.parseInt(vars.get(Metrics.SUBTASK_INDEX));
}
if (useCustomReporter()) {
customReporter =
DataSyncFactoryUtil.discoverMetric(
config, getRuntimeContext(), makeTaskFailedWhenReportFailed());
customReporter.open();
}
startTime = System.currentTimeMillis();
}
- nextRecord:通过调用nextRecordInternal读取一条记录,然后更新durationCounter;
- close:关闭InputFormat的相关资源,调用closeInteral实现;
- closeInputFormat:关闭限速器、累加器和指标发布器;
- initAccumulatorCollector:初始化累加器方法;
- initByteRateLimiter:限流器初始化方法;
- initStatisticsAccumulator:累加指标初始化方法;
- initRestoreInfo:从检查点中恢复指标数据;
- getFormatState:返回FormatState,没有则重新设置;
增量同步相关两个自定义方法:
- useCustomReporter:是否将指标输出到发布器customReporter;
- makeTaskFailedWhenReportFailed:发布指标失败时是否将任务置为失败;
剩余的是字段setter、getter方法和留给子类实现的openInternal、nextRecordInternal方法,不再复述。下篇文章分析BaseRichInputFormat提供插件通用功能:限流、指标统计、指标发布是如何实现的。
总结
- InputFormat根据InputSplit划分读取记录的范围,而InputSplitSource可以看成InputSplit的工厂抽象。
- InputFormat的生命周期:初始化配置(configure)、打开资源(openInputFormat)、打开InputSplit读取(open)、是否读取完毕(reacheEnd)、关闭InputSplit(close)、关闭资源(closeInputFormat);
- FlinkX的BaseRichInputFormat是所有读插件InputFormat的抽象基类,统一实现了指标收集、发布和限流的功能,而子类只需要实现createInputSplitsInternal、openInternal、closeInternal和nextRecordInternal方法。