分层存储
info
Mastering Apache Pulsar 第9章读书笔记
Pulsar分层存储(Tiered Storage)机制将消息持久化到其他存储服务,如下图所示:
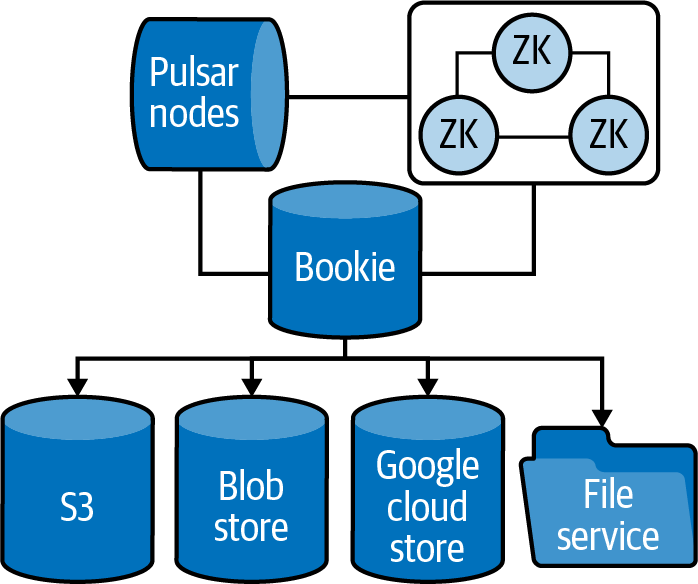
云存储
鉴于Pulsar的云原生特性,优先关注云存储机制:块存储、文件存储和对象存储。三者成本依次递减,本节着重对象存储。
| 类型 | 成本 | 使用场景 |
|---|---|---|
| Block | 💰💰💰 | 云存储 |
| File | 💰💰 | 网络附加存储 |
| Object | 💰 | 云存储、大数据存储 |
对象存储
对象存储与文件存储不同,其范式包含:数据、元数据、权限、对象ID。对象没有放在分层的文件系统,而是桶(bucket)中:
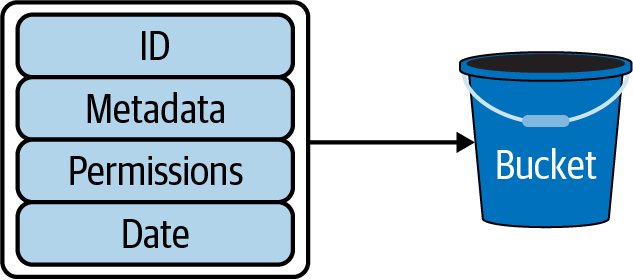
在第4章中提到BookKeeper也被某项项目用作对象存储,两者比较如下:
| 对比项 | 对象存储 | BookKeeper Ledger |
|---|---|---|
| 存储方式 | 字节存储 | 字节存储 |
| 是否需要元数据 | 是 | 大部分场景需要 |
| 是否需要权限 | 是 | 否,但可以实现 |
| 唯一ID | 每个对象有唯一ID | 每个ledger有唯一ID |
使用场景
- 备份:分层存储本身就是一种备份机制;
- CQRS:命令查询责任分离(Command Query Responsibility Segregation)机制指读写分离,通过Pulsar写数据,当数据稳定后同步到外部存储系统,通过其读数据;
- 灾难恢复:通过分层存储将数据卸载到可靠系统,通过冗余进行数据恢复。
卸载数据
Pulsar Offloader
Offloader是卸载数据配置的抽象,如下图所示,Apache Pulsar通过Apache jClouds实现分层存储。
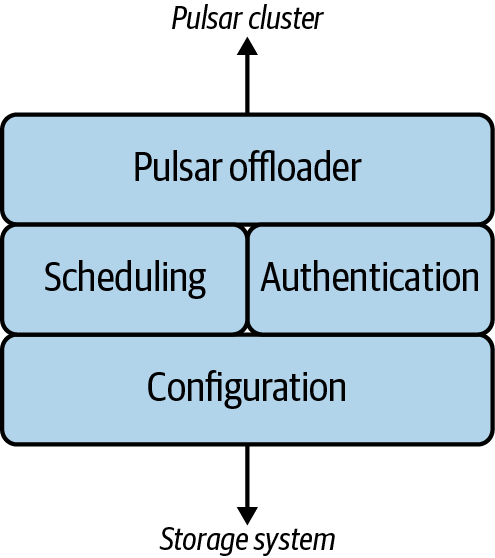
使用Amazon S3和Google Cloud Storage作为对象存储后端的配置过程:
- 在云服务上创建桶和服务账号;
- [S3]编辑conf/pulsar_env.sh添加AWS认证;
- 编辑broker.conf文件;
- 启动broker。
获取卸载数据
通过对象存储系统
在CQRS场景下通过对象存储系统直接获取卸载数据,注意获取数据可能需要解码。
重填topic
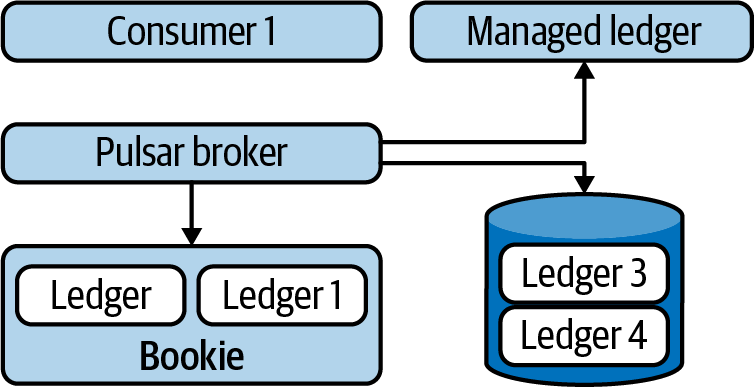
将卸载数据加载到topic,由消费者获取(例如构建source连接器读取S3中的ledger),如下图所示:

使用Pulsar Client
Manager ledger不但告诉应该去哪个ledger读取信息,还保存该ledger存储位置信息,作为消费者不需要关心ledger在哪,只需要读取topic。因此获取卸载数据的最简单方式就是使用Pulsar Client。
import org.apache.pulsar.client.api.MessageId;
import org.apache.pulsar.client.api.Reader;
Reader<byte[]> reader = pulsarClient.newReader()
.topic("read-from–topic")
.startMessageId(MessageId.earliest) // get data at earliest offset
.create();
while (true) {
Message message = reader.readNext();
// Get messages after this point
}
注意
Consumer通过订阅机制读取消息而Reader没有。
总结
Pulsar分层存储机制指消息持久化到其他外部存储系统,使得Pulsar提供数据备份、灾难恢复和CQRS功能。