Pulsar SQL
info
Mastering Apache Pulsar 第10章读书笔记
以流为表
以一场篮球比赛的计分应用为例,使用流处理模型时可以构建如下schema:
{
"team" : <team_id>,
"event": "score",
"points": <number>
}
通过对消息的聚合计算,可以得到总比分情况,就像创建了一个表视图。总结来说就是对数据流进行聚合操作可以将流作为表使用。
以一个订单消息流为例,不同时间的消息可以视为订单表中的记录,可以通过SQL统计各项指标:
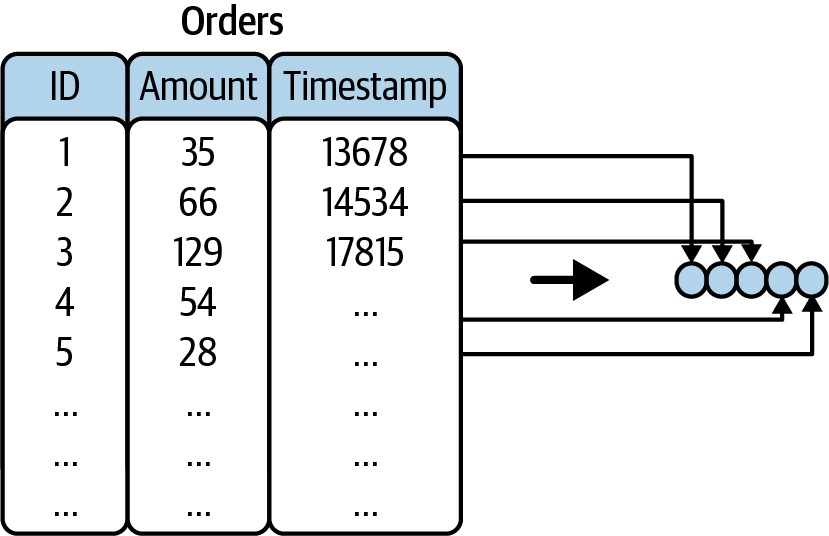
# 统计过去24小时内订单总量
Select sum(amount) from orders where time_stamp_function(timestamp, 24h);
SQL-on-Anything引擎
数据流是无界的,既然以流为表,那一个无限记录的表意味着什么?回答这个问题先要理解查询数据和数据流的历史。
21世纪初雅虎公司的Doug Cutting和Mike Cafarella开发了分布式数据存储系统Hadoop。与传统关系型数据库不同,Hadoop将存储和计算解耦,数据存储和数据计算不在同一台物理机上。早期Hadoop并没有提供类SQL接口,用户通过编写MapReduce程序来操作计算数据,随后Hive出现解决了这个问题。
但Hive SQL引擎也存在不足:性能低、部署结构复杂,以Presto和Spark为代表的项目被开发来解决Hive的问题。随着工业界转向使用对象存储和流平台,在这些系统上使用SQL的需求也逐渐显露。Spark和Presto是知名的SQL-on-Anything引擎,在不同系统之上提供SQL查询能力。对于Pulsar,Presto在topic之上提供SQL引擎,即Pulsar SQL。
Why Not Apache Flink SQL
Flink SQL也提供SQL-on-Streams引擎,为什么Pulsar选择Presto而不是Flink SQL?主要原因是Presto是可嵌入式的,而Flink SQL需要额外部署。
Presto/Trino
Presto由Facebook主导开发,尽管许多公司参与该项目,但最终Facebook决定哪些新特性会被合入到Presto,因此一些开发者基于该项目fork了一个新项目Trino,由开源基金会PrestoDB Found管理。
Apache Pulsar使用Trino,后文都将会Presto称为Trino。
Puslar SQL工作机制
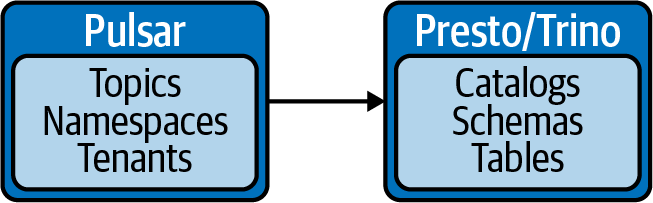
Pulsar SQL核心是一个Trino connector,该connector作为consumer使用存在topic的元数据查询数据,如下图所示Pulsar和Trino的概念互为映射:
Trino集群架构如下图所示,worker与外部系统交互,coordinator协调管理并存储元数据:

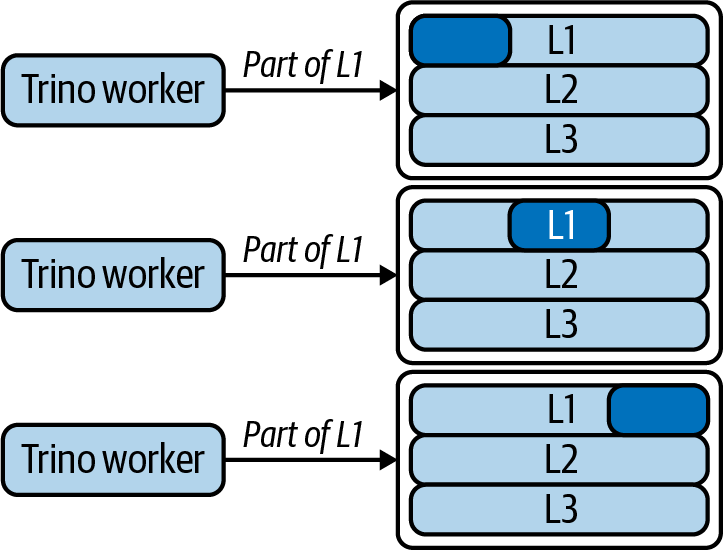
实现Pulsar SQL有2种方式:从topic读取数据、从存放处(BookKeeper、对象存储等)读取数据。由于Pulsar将数据存放在BookKeeper,并且BookKeeper存储是冗余的,因此可以并发读取ledger的不同部分,从而提高SQL查询速度,如下图所示:
Pulsar SQL配置
# name of the connector to be displayed in the catalog
connector.name=pulsar
# the url of Pulsar broker service
pulsar.web-service-url=http://localhost:8080
# URI of Zookeeper cluster
pulsar.zookeeper-uri=localhost:2181
# minimum number of entries to read at a single time
pulsar.entry-read-batch-size=100
# default number of splits to use per query
pulsar.target-num-splits=4
public class Test {
public static class Person {
private int id = 1;
private String name;
private long date;
}
public static void main(String[] args) throws Exception {
PulsarClient pulsarClient = PulsarClient.builder()
.serviceUrl("pulsar://localhost:6650").build();
Producer<Person> producer = pulsarClient
.newProducer(AvroSchema.of(Person.class)).topic("person_topic")
.create();
for (int i = 0; i < 1000; i++) {
Person person = new Person();
person.setid(i);
person.setname("foo" + i);
person.setdate(System.currentTimeMillis());
producer.newMessage().value(person).send();
}
producer.close();
pulsarClient.close();
}
}
- 开启Pulsar集群:
./bin/pulsar sql-worker start; - 开启Pulsar SQL:
./bin/pulsar sql; - 执行sql:
select * from pulsar."public/default".person_topic;
性能考虑
Trino的并发架构意味着可以垂直、水平扩展,实际测试性能如下:
- 3节点,12核CPU,128GB内存,2块1.2TB NVME硬盘;
- 解析压缩JSON每秒约6千万行,解析压缩Avro每秒约5千万行。
总结
Pulsar SQL使用Trino作为SQL引擎,通过Trino和BookKeeper的分布式存储架构提高SQL执行速度。