状态流处理简介
info
Stream Processing with Apache Flink 第1章读书笔记
传统数据架构
传统数据架构处理数据的方式分为两种:事务型处理(Transactional Processing)和分析型处理(Analytical Processing)。
事务型处理
以ERP、CRM和Web应用为代表,传统架构如下图所示:
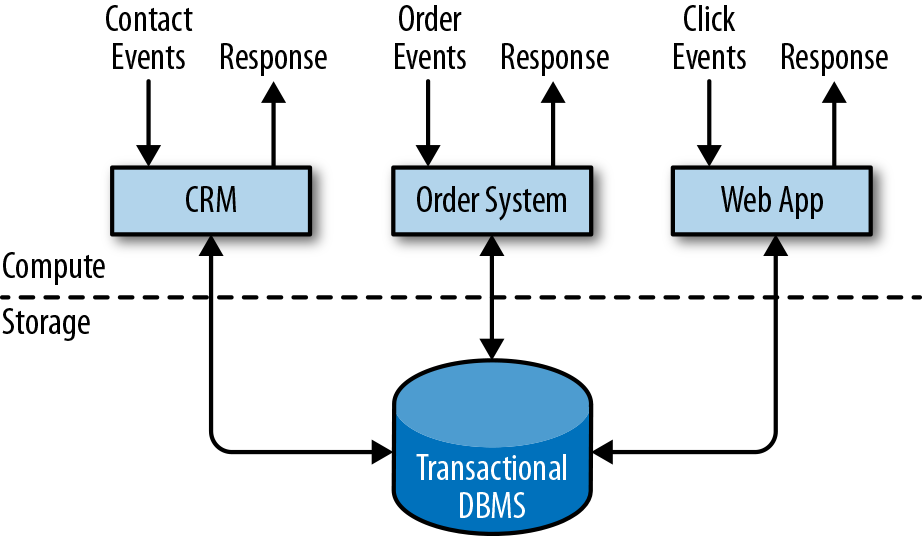
特点:由事件(Event)触发,基于后台数据库系统的事务进行数据增删改查。通常一个数据库系统服务多个应用,这些应用可能访问相同库表。
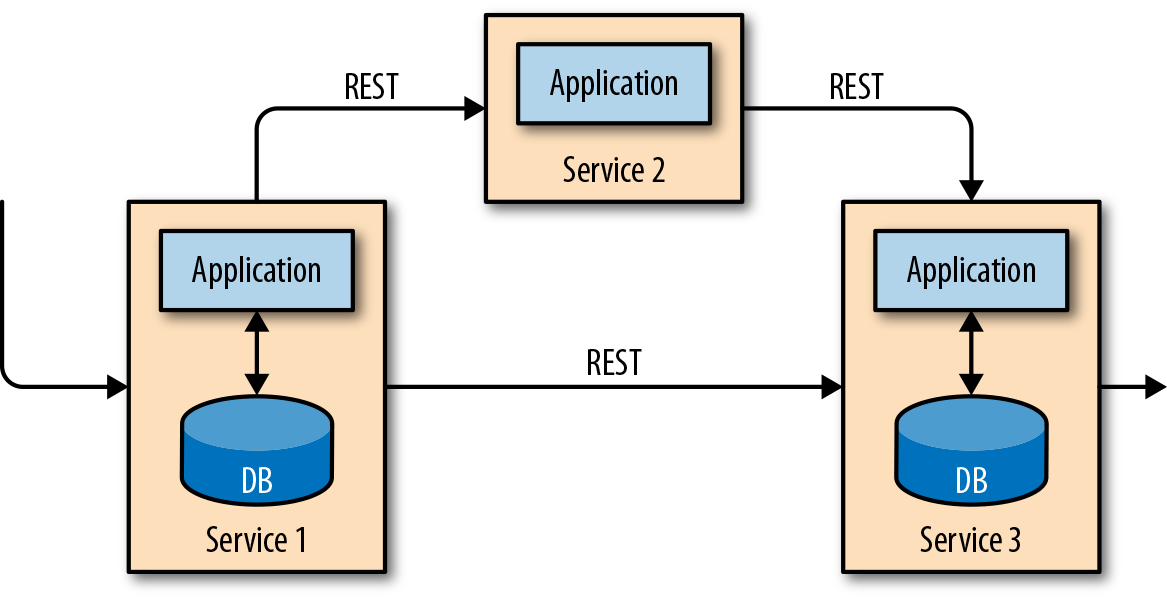
缺点:随着应用的演化扩展,改变库表设计或者扩展数据库费劲。一种解决方式是微服务(Microservice)解耦,服务之间使用REST的HTTP通信,如下图所示:
分析型处理
事务型数据分布在各个互相独立的数据库中,需要将它们集中转为统一格式后分析产生更大价值,架构如下所示:
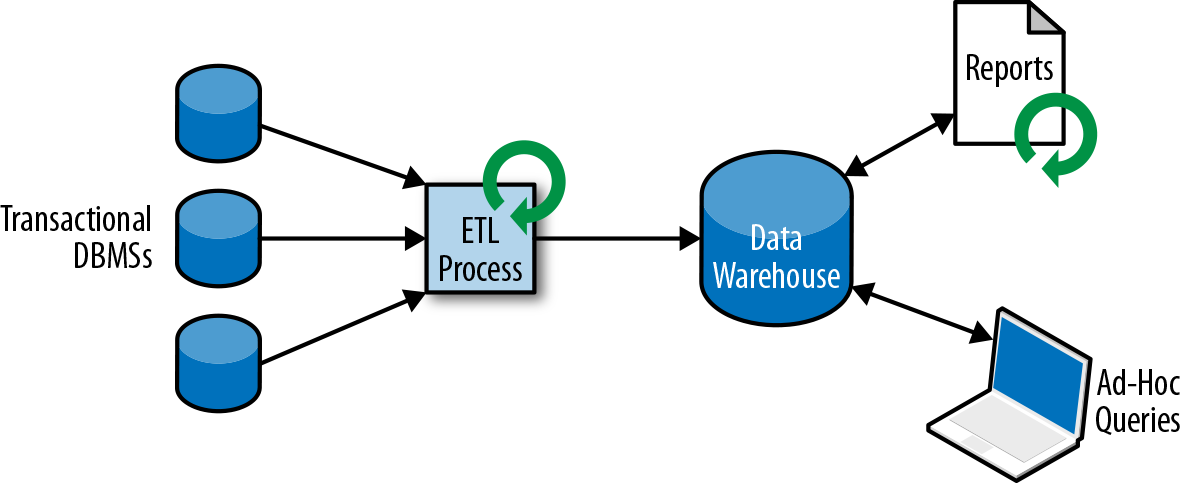
首先通过ETL(Extract-Transform-Load)将分散的数据复制到数据仓库(Data Warehouse)中,然后进行分析。通常,基于数据仓库的查询分析有两种:
- Periodic report query:周期报告查询,计算商业相关统计指标如营收、用户增长等;
- Ad-hoc query:热点查询,用于回答特定问题如广告的收入和支出比例。
状态流处理
几乎所有数据以事件流的形式产生,而不是一次产生有限的数据集(Dataset)。状态流处理指处理无界数据流的应用设计模式,并且需要保存应用状态。
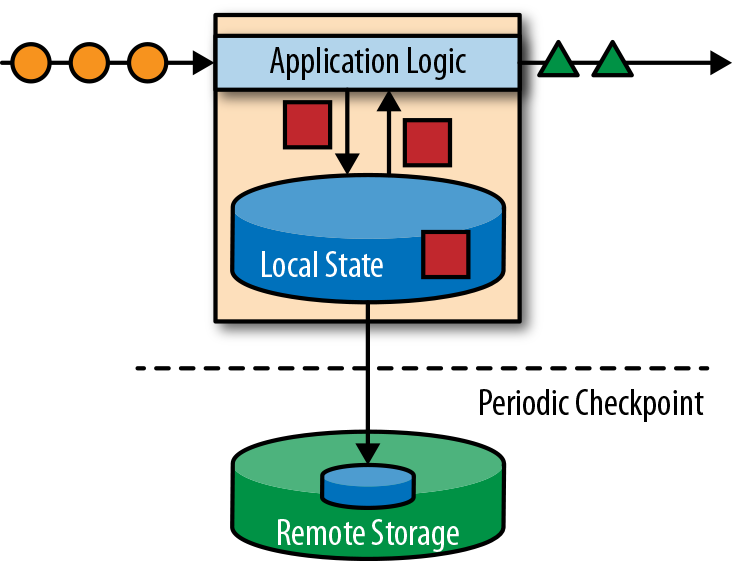
Flink将应用状态保存在本地内存或者嵌入式数据库,由于Flink是分布式的,它通过持久化一致性检查点到远程存储来保证容错性。一个Flink应用的状态流处理过程如下图所示:
下面介绍3种典型的流处理应用:事件驱动型应用、数据流水线型应用和数据分析型应用。
事件驱动型应用
典型的数据驱动型应用包括:
- 实时推荐
- 模式检测或者复杂事件处理
- 异常检测
事件驱动型应用是微服务的一种演变体:通信使用事件日志而不是REST调用,数据保存为应用本地状态而不是保存到外部数据源(如MySQL数据库、Redis)。数据驱动型应用架构如下所示:
相比于传统应用或者微服务,事件驱动型应用优势:
- 获取本地状态的性能优于获取远程数据源
- 扩展和容错由流处理器(Stream Processor,非硬件上概念)处理
- 利用事件日志作为输入的优势:可靠、可重放(replay)
- 通过检查点重置应用状态,该升级或扩展应用时不会丢失状态
但为了实现上述的特性,事件驱动型应用对流处理器有着高要求:比如提供的API和状态原语(State Primitives)。此外,“精准一次”的状态一致性和扩展能力是事件驱动型应用的基本要求,比如说Flink就很好地满足这些条件😊。
数据流水线
当前的数据存储使用不同的系统将数据用不同的结构保存起来,以在特定访问模式的获取最佳性能。同步这些存储数据的传统方式是用周期性ETL作业,为了满足低延迟要求,一种替代方式是使用事件日志发布更新。
在低延迟下获取、转化、插入数据是状态流处理程序的另一种使用场景,这种程序称之为数据流水线(Data Pipeline),它要在短时间内完成大量数据同步,并能支持不同数据源读写,Flink再一次地满足这些条件😄。
流数据分析
数据流水线需要等待周期性事件触发,而流分析型应用不断地获取事件,并根据最新事件更新结果来实现低延迟。通常把结果存在支持高效更新的外部数据存储,如数据库和Redis,如下图所示:
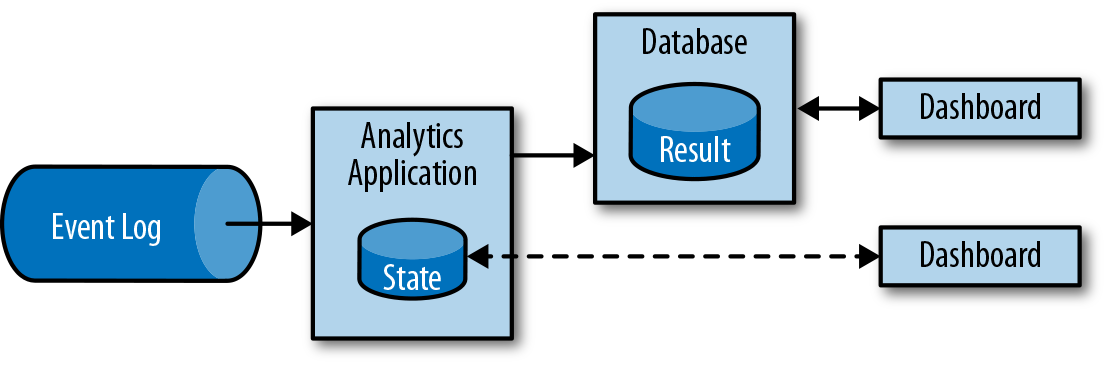
流分析应用通常用于分析移动应用的用户行为,消费者实时数据分析等
流处理的演变
数据流处理并不是新兴技术,下面介绍开源流处理技术的发展历程:
第一代数据流处理架构以结果准确性换区低延迟,处理结果依赖于事件到达的顺序和时间。而批处理高延迟但结果准确,由此诞生了结合两者的lambda架构,如下图所示:
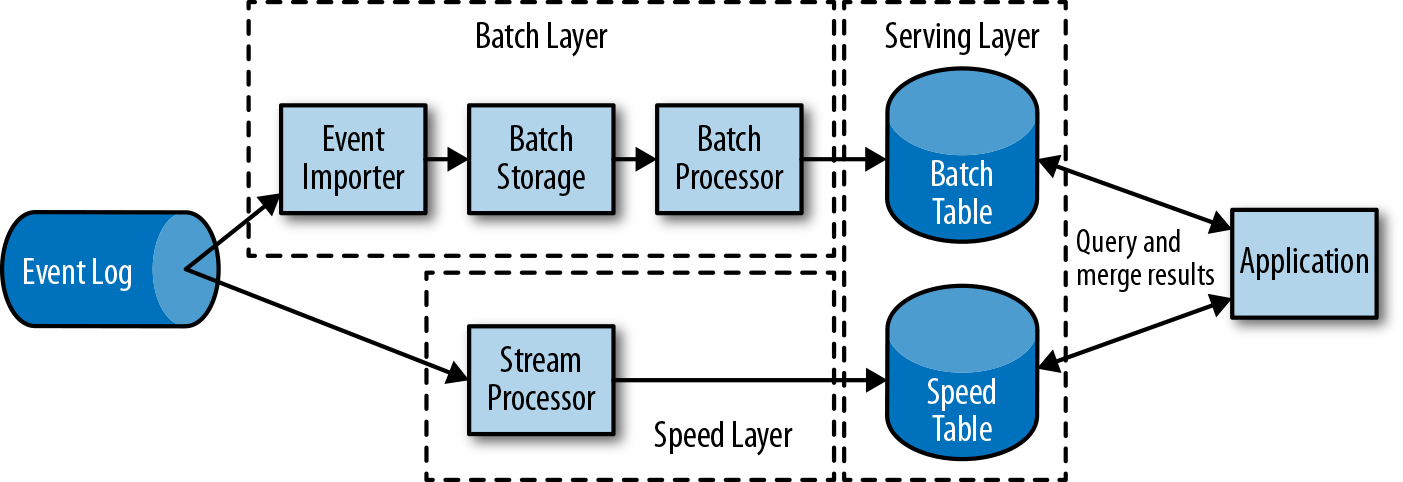
在lambda架构中,数据处理分为结果不准确的加速层和结果准确的批处理层。流处理得到的结果和批处理结果分别存放,将两者合并得到最终结果。lambda架构的缺点:
- 需要用2种不同API实现相同逻辑的功能
- 流处理器的计算结果只是大概的
- 难以搭建和维护
第二代流处理技术在以秒级延时为代价,提升了吞吐率和容错性,但结果还是依赖事件时间和顺序。
第三代架构处理了时间到达时间和顺序对结果的影响,结合exactly-once失败语义,能够计算一致和精准的结果。此外相比于第二代,兼顾高吞吐率和低延迟,淘汰了lambda架构😏。